Przetwarzanie danych informatycznych w chmurach obliczeniowych. Wybrane aspekty prawnokarne i procesowe
Chmura obliczeniowa: kompletny przewodnik
Co to jest chmura obliczeniowa?
Chmura, chmura obliczeniowa lub z angielskiego cloud computing to terminy oznaczające model licencjonowania i dostarczania zasobów informatycznych – infrastruktury, usług, platform oraz aplikacji za pośrednictwem sieci. Zasoby IT są udostępniane na żądanie, a opłaty naliczane za ich faktyczne zużycie.
Chmura obliczeniowa jest w rzeczywistości zwirtualizowaną pulą zasobów sprzętowych (m.in. procesor, pamięć operacyjna, pamięć masowa), którą zarządza oprogramowanie zwane z ang. hypervisorem. Dzięki niemu możliwe jest dowolne modyfikowanie parametrów zasobów na żądanie, w zależności od wymagań użytkownika. W Oktawave korzystamy z oprogramowania do wirtualizacji rozpoznawanej szeroko marki VMware.
Chmura obliczeniowa pozwala znacząco zoptymalizować koszty IT. Nie trzeba bowiem ponosić wydatków związanych z zakupem i utrzymaniem własnej infrastruktury oraz wielu innych kosztów stałych. W cloud computingu, opłaty naliczane są jedynie za moc obliczeniową wykorzystaną w danym okresie i stanowią one dla użytkownika koszt operacyjny.
Rodzaje chmur obliczeniowych
Chmura to tak naprawdę zbiorcza nazwa. Możemy wymienić jej trzy rodzaje: publiczną, prywatną, hybrydową.
Zbudowana z zasobów nie należących do użytkownika końcowego. Z chmur publicznych korzystamy wszyscy, chociaż niekoniecznie zdajemy sobie z tego sprawę. Takim rodzajem chmury obliczeniowej jest m.in. poczta Gmail w Google, zestaw narzędzi w pakiecie Office 365 Microsoft Azure czy usługi platformy oraz infrastruktury w Amazon Web Services. Aplikacje natywne osadzone i serwowane z chmury charakteryzują się otwartym dostępem dla wszystkich użytkowników z dowolnego miejsca na świecie, które ma dostęp do internetu.
Więcej>
Zbudowana z zasobów należących fizycznie lub dzierżawionych przez użytkownika. Jej podstawowy wyróżnik to ograniczony dostęp z zewnątrz. Z jej usług obliczeniowych mogą korzystać tylko użytkownicy z danej organizacji. Dlatego chmura prywatna nazywana jest również chmurą wewnętrzną lub korporacyjną. Za utrzymanie takiej chmury odpowiada dział IT firmy, a pozostałe jednostki biznesowe są jej wewnętrznymi użytkownikami. Rozwiązanie typu private cloud jest z reguły bardziej kosztowne od chmury publicznej szczególnie w wariancie, gdy decydujemy się zbudować własną infrastrukturę.
Więcej>
Składa się z połączonych zasobów chmury prywatnej i publicznej. W obrębie jednej architektury można np. do zadania A wykorzystać moc obliczeniową jednej chmury, a do zadania B storage obiektowy chmury drugiej. Zasoby dwóch typów chmur w takim układzie uzupełniają się i wspierają. Nasi eksperci od migracji pomagają firmom tak zaprojektować architekturę hybrid cloud, aby utrzymać koszty na optymalnym poziomie.
Więcej>
Jeszcze do niedawna pełne wykorzystanie usług chmur obliczeniowych było bardzo trudne. Z tego powodu inwestowano zazwyczaj w usługi kilku dostawców (najczęściej konkurencyjnych). Dziś rozwiązaniem tego problemu jest multicloud.
Multicloud bazuje na połączeniu usług więcej niż jednej chmury obliczeniowej. W pewnym sensie jest to rodzaj strategii, która umożliwia korzystanie z kilku usług jednocześnie. W praktyce wygląda to tak, że jedną chmurę wykorzystujemy np. do analizy danych, a drugą do tworzenia kopii zapasowych. Należy jednak rozdzielić pojęcie multicloud od chmury hybrydowej. Hybryda łączy prywatne serwery z publicznymi chmurami, integrując także sprzęt. Multicloud obejmuje tylko usługi chmurowe.
Więcej>
Modele dostarczania usług w chmurze
Aby optymalnie spełnić wymagania klienta, usługi chmurowe zostały podzielone na trzy modele: IaaS, PaaS, SaaS.
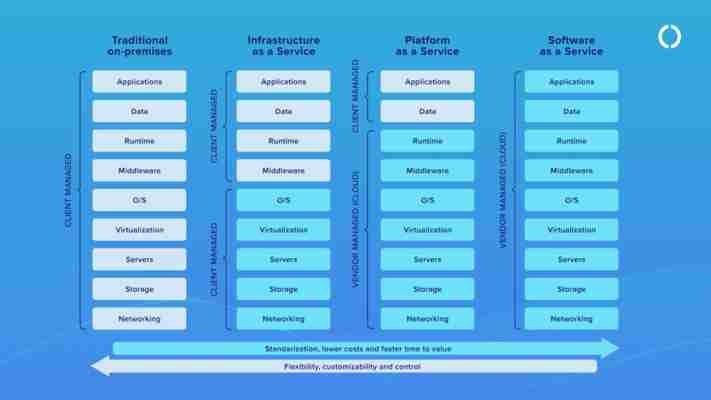
Infrastruktura jako usługa jest podstawą każdego wdrożenia w chmurze. Oferuje dostęp zarówno do wybranych wirtualnych zasobów sprzętowych (sieci, pamięci masowej, serwerów i wirtualizacji), jak i możliwość instalacji dodatkowych usług rozszerzających jej funkcjonalność. Pozostałe części stosu technologicznego – od systemu operacyjnego do aplikacji są w IaaS zarządzane samodzielnie przez użytkownika. W Oktawave można tworzyć instancje serwera z już zainstalowanym systemem operacyjnym.
Więcej>
Platforma jako usługa, to warstwa dodatkowa oprogramowania zbudowana na fundamencie IaaS. W praktyce oznacza to udostępnienie zasobów sprzętowych wraz z gotowym stosem różnych technologii, które uławiają programistom szybszy rozwoj i wdrażanie aplikacji użytkownika. Dostawcy PaaS oferują zatem w pakiecie infrastrukturę, serwery, sieci, pamięć masową, bazę danych, oprogramowanie pośrednie, system operacyjny (OS), bezpieczeństwo, środowisko wykonawcze, monitorowanie infrastruktury, analizy i możliwość integracji z usługami innych firm. Przykładem usługi PaaS może być AWS Elastic Beanstalk, Google App Engine czy Red Hat OpenShift.
Więcej>
Oprogramowanie jako usługa, to warstwa usług chmurowych, w której w pełni funkcjonalne i kompletne oprogramowanie – zbudowane na IaaS i PaaS – jest dostarczane do użytkowników przez Internet na zasadzie subskrypcji. SaaS jest najbardziej powszechnym rodzajem usług chmurowych ze wszystkich powyższych. W rzeczywistości wielu użytkowników korzysta z SaaS nawet nie zdając sobie z tego sprawy. Przykładem może być tu choćby pakiet MS Office 365, usługa Dropbox, czy Netflix.
Więcej>
Serverless computing, czyli przetwarzanie bezserwerowe, to popularna usługa typu FaaS (Function as a Service) oferowana przez największych dostawców chmury: Lambda AWS, Azure Functions i Cloud Functions w Google Cloud.
To model tworzenia oprogramowania, w którym korzystasz z dynamicznie przyznanych zasobów i pamięci obliczeniowej przed dostawcę chmury. W przeciwieństwie do tradycyjnego modelu, w którym wykupujesz określone zasoby i płacisz za nie, nawet jeśli nie są w pełni wykorzystane. W przypadku serverless procedury i funkcje składające się na aplikację, uruchamiane są tylko w momencie potrzeby przetwarzania danych, a gdy są bezczynne, zasoby nie są zużywane. Użytkownik płaci jedynie za wykonanie funkcji. Zarządzanie infrastrukturą, w tym jej przydzielanie i optymalizowanie, jest całkowicie po stronie dostawcy chmury.
Termin „bezserwerowy” jest nieco mylący, ponieważ sugeruje brak serwerów. Serwery w rzeczywistości istnieją, ale programiści nie muszą zajmować się ich obsługą. Dzięki temu mogą w pełni skupić się na tworzeniu aplikacji, zamiast dbać o konfigurację, skalowanie i bezpieczeństwo maszyn wirtualnych, serwerów czy kontenerów.
Więcej>
Technologie chmury
Disaster Recovery (DR), czyli odtwarzanie awaryjne, to zbiór procedur i polityk pozwalający na wznowienie lub utrzymanie infrastruktury IT po poważnej awarii. Awaria może być skutkiem szkodliwej działalności człowieka (nieumyślnej lub umyślnej, jak np. cyberatak) czy klęski żywiołowej (pożar, powódź, trzęsienie ziemi, tsunami itp.). Katastrofa może spowodować uszkodzenie infrastruktury i uniemożliwić działalność biznesową.
Więcej >
Wysoka dostępność (ang. High Availability, w skrócie HA) to odporność poszczególnych komponentów infrastruktury informatycznej na awarię, która umożliwia funkcjonowanie uruchomionych aplikacji bez zakłóceń. HA jest szczególnie ważne w przypadku krytycznych systemów, dla których przestój w działaniu oznacza poważne szkody, również finansowe. Jednym z głównych celów przejścia do chmury jest właśnie osiągnięcie niezawodności. Systemy o wysokiej dostępność eliminują pojedyncze punkty awarii (SPOF), aby zapewnić ciągłość działania i uchronić firmę przed utratą danych.
Więcej >
Powstanie technologii konteneryzacji to konsekwencja dążenia twórców aplikacji do architektury mikroserwisów. Zarządzanie złożonymi, rozproszonymi systemami mikroaplikacji stało się sporym wyzwaniem logistycznym, stąd odniesienie do idei kontenerów w branży logistycznej. Podzielone na mniejsze elementy aplikacje umieszcza się w kontenerach czyli wydzielonych obszarach maszyny wirtualnej. Kontener zawiera wszystko (kod źródłowy, biblioteki systemowe, pliki konfiguracyjne itp.), co niezbędne do uruchomienia aplikacji. Dzięki temu aplikację można szybko przenieść i uruchomić w innym środowisku, bez konieczności jego ponownego, ręcznego konfigurowania.
Więcej >
Mikroserwisy to termin określający architekturę aplikacji i sposób ich pisania. W odróżnieniu od monolitycznych rozwiązań, których zasada działania opiera się na rozmieszczeniu poszczególnych części aplikacji w jej wnętrzu (z wykorzystaniem relacyjnego modelu danych), mikroserwisy dzielą je na mniejsze, niezależne od siebie komponenty. Mikroserwisy są zatem oddzielnymi częściami tej samej aplikacji – komponentami lub procesami.
Więcej >
Termin cloud-native można przetłumaczyć jako natywny dla chmury. Określenie to odnosi się do podejścia do tworzenia oprogramowania, które wykorzystuje technologię przetwarzania w chmurze. Aplikacje budowane są od początku z myślą o chmurze i z wykorzystaniem jej architektury oraz technologii (np.: mikroserwisy, kontenery, serverless). Systemy cloud-native korzystają z dostępnych w chmurze usług zarządzanych i narzędzi do automatyzacji. Rozwiązania natywne dla chmury złożone są z luźno powiązanych systemów (mikroserwisów) które w przeciwieństwie do aplikacji monolitycznych, można szybko budować, wdrażać, skalować, a także wygodnie nimi zarządzać.
Więcej >
Wirtualizacja to proces logicznego podzielenia fizycznego urządzenia (np. serwera) na mniejsze wirtualne jednostki. Oprogramowanie zwane hiperwizorem pozwala podzielić zasoby fizyczne na jednej maszynie na wiele maszyn wirtualnych (VM). Każda maszyna wirtualna staje się osobnym obszarem, na którym można uruchomić osobne środowisko ze swoim systemem operacyjnym. Wirtualizacja jest podstawową technologią wykorzystywaną w cloud computingu. Pozwala dzielić i błyskawicznie przydzielać zasoby pomiędzy wieloma systemami w zależności od potrzeb. Dzięki skalowalności chmury możemy wygodnie zarządzać pamięcią i optymalnie wykorzystać serwery. Jakie korzyści stwarza wirtualizacja?
Więcej >
Potencjał chmury obliczeniowej można w pełni wykorzystać, poznając jej zastosowania.
Więcej >
Chmura obliczeniowa to innowacyjne rozwiązanie, które niesie ze sobą szereg korzyści biznesowych i technologicznych. Umiejętne wykorzystanie ich zwiększa wydajność nie tylko zasobów IT, ale również całego przedsiębiorstwa. Jakie to korzyści?
Więcej >
Jednym z powodów, dla których firmy decydują się na migrację do chmury, obok skalowalności i bezpieczeństwa, jest jej opłacalność. Tradycyjna serwerownia oznacza nie tylko koszty sprzętu i powierzchni, ale również utrzymanie zespołu odpowiedzialnego za obsługę, koszty konserwacji, napraw, zabezpieczeń i wreszcie energii elektrycznej.
Więcej >
Pierwszym krokiem, który należy wykonać jest tzw. „spis z natury”, czyli lokalny audyt. W ramach takiego audytu powinna powstać pełna lista systemów informatycznych działających w firmie, które potencjalnie mogą zostać przeniesione do chmury.
Więcej >
Wybór zarówno technologii, jak i jej dostawcy jest niezwykle ważny, ponieważ przesądza o sukcesie firmy w długoterminowym ujęciu. Technologia determinuje tempo i zakres rozwoju organizacji, a odpowiednie wsparcie ze strony dostawcy ma duże znaczenie dla skuteczności, sprawności, a także opłacalności wdrażanych rozwiązań. Decydując się na przejście do chmury, firma musi zdecydować nie tylko o rodzaju chmury (prywatna, publiczna czy hybrydowa), ale też o zakresie usług dodatkowych.
Więcej >
Chmura obliczeniowa – Wikipedia, wolna encyklopedia
Diagram przedstawiający „chmurę”
Chmura obliczeniowa[1], przetwarzanie w chmurze (ang. cloud computing) – model przetwarzania danych oparty na użytkowaniu usług dostarczonych przez usługodawcę (wewnętrzny dział lub zewnętrzną organizację). Chmura to usługa oferowana przez dane oprogramowanie (oraz konieczną infrastrukturę). Oznacza to eliminację konieczności zakupu licencji czy konieczności instalowania i administracji oprogramowaniem. Konsument płaci za użytkowanie określonej usługi, np. za możliwość korzystania z arkusza kalkulacyjnego. Nie musi dokonywać zakupu sprzętu ani oprogramowania. Umowa zawierana na świadczenie usług w chmurze obliczeniowej przeważnie nie jest tworzona pod konkretny podmiot, lecz zawiera pakiet rozwiązań zestandaryzowanych[2]. Termin „chmura obliczeniowa” jest związany z pojęciem wirtualizacji. Model „chmury obliczeniowej” historycznie wiąże się z przetwarzaniem w sieci grid, gdzie wiele systemów udostępnia usługi korzystając z podłączonych zasobów, z tą różnicą, że w chmurze obliczeniowej mamy do czynienia z podążaniem zasobów za potrzebami usługobiorcy.
Zasada działania chmury obliczeniowej [ edytuj | edytuj kod ]
Zasada działania polega na przeniesieniu całego ciężaru świadczenia usług IT (danych, oprogramowania lub mocy obliczeniowej) na serwer i umożliwienie stałego dostępu poprzez komputery klienckie. Dzięki temu ich bezpieczeństwo nie zależy od tego, co stanie się z komputerem klienckim, a szybkość procesów wynika z mocy obliczeniowej serwera. Wystarczy zalogować się z jakiegokolwiek komputera z dostępem do Internetu by zacząć korzystać z dobrodziejstw chmury obliczeniowej.
Pojęcie chmury nie jest jednoznaczne, w szerokim znaczeniu przetwarzanym w chmurze jest wszystko przetwarzane na zewnątrz zapory sieciowej, włączając w to konwencjonalny outsourcing[3].
Rodzaje chmur [ edytuj | edytuj kod ]
Rozróżniamy chmury:
prywatne (ang. private cloud ), będące częścią organizacji, aczkolwiek jednocześnie autonomicznym dostawcą usługi
), będące częścią organizacji, aczkolwiek jednocześnie autonomicznym dostawcą usługi publiczne (ang. public cloud ), będące zewnętrznym, ogólnie dostępnym dostawcą (np. Amazon Web Services, Google Cloud Platform, Microsoft Azure itp.)
), będące zewnętrznym, ogólnie dostępnym dostawcą (np. Amazon Web Services, Google Cloud Platform, Microsoft Azure itp.) hybrydowe (ang. hybrid), będące połączeniem zasad funkcjonowania chmury prywatnej i publicznej. Pewna część aplikacji i infrastruktury danego klienta pracuje w chmurze prywatnej, a część jest umiejscowiona w przestrzeni chmury publicznej[4].
Na przykładzie arkusza kalkulacyjnego, klient płaci za możliwość tworzenia arkuszy, nie jest natomiast świadomy, gdzie oprogramowanie jest fizycznie zainstalowane, na jakim sprzęcie, ani gdzie zapisywane są dane oraz jakie inne usługi są wykorzystywane by dostarczyć tę, którą jest zainteresowany. Cloud oznacza wirtualną chmurę usług dostępnych dla klienta, w której ukryte są wszelkie szczegóły, których świadomość jest zbędna w korzystaniu z usługi.
Modele chmury obliczeniowej [ edytuj | edytuj kod ]
Współcześnie coraz więcej nowych funkcji realizowanych jest w modelu chmur obliczeniowych. Kwestią czasu jest dojście do szczytu wirtualizacji – przeniesienia całego oprogramowania (wraz z systemem operacyjnym) na serwer, a u użytkownika instalacja cienkiego klienta, mającego tylko interfejsy komunikacji z obsługującą go osobą. Taki cienki klient przy szybkich łączach internetowych mógłby się łączyć z serwerem niebędącym w sieci lokalnej, ale umiejscowionym gdziekolwiek na świecie. To prowadzi do dodatkowej funkcji SaaS – DaaS (ang. desktop as a service). W takim modelu użytkownik kupowałby od usługodawcy hostowaną przez niego maszynę wirtualną, w pełni spersonalizowaną i posiadającą dokładnie taką specyfikację, jakiej oczekuje[5].
Kolokacja to najstarsza i najprostsza forma usług w chmurze. Polega na wynajęciu pomieszczenia serwerowni, dostępu do energii elektrycznej, klimatyzacji i dostępu do Internetu. Pozostałe składniki – sprzęt, zabezpieczenia (zapory), zarządzanie obciążeniem, system operacyjny, oprogramowanie i aplikacje opłaca firma korzystająca. Jest to zatem opłata za użyczenie miejsca w serwerowni[6].
Osobny artykuł: Infrastructure as a Service.
Infrastructure as a Service (z ang. „infrastruktura jako usługa”) – model polegający na dostarczaniu klientowi infrastruktury informatycznej, czyli sprzętu, oprogramowania oraz serwisowania. Klient wykupuje na przykład konkretną liczbę serwerów, przestrzeni dyskowej lub określony zasób pamięci i mocy obliczeniowej. Nie oznacza to jednak, że sprzęt fizycznie zostanie zainstalowany w siedzibie klienta. W tym modelu zdarza się, że klient dostarcza usługodawcy własne oprogramowanie do zainstalowania na wynajmowanym sprzęcie.
Osobny artykuł: Platform as a Service.
Platform as a Service (z ang. „platforma jako usługa”) – sprzedaż gotowego, często dostosowanego do potrzeb użytkownika, kompletu aplikacji. Nie wiąże się z koniecznością zakupu sprzętu ani instalacją oprogramowania. Wszystkie potrzebne programy znajdują się na serwerach dostawcy. Klient po swojej stronie ma dostęp do interfejsu (na ogół w postaci ujednoliconego środowiska pracy) poprzez program – klienta, np. przeglądarkę internetową. W tym modelu, usługi najczęściej dostępne są dla użytkownika z dowolnego komputera połączonego z internetem.
Osobny artykuł: Software as a Service.
Software as a Service (z ang. „oprogramowanie jako usługa”) – klient otrzymuje konkretne, wybrane funkcje oprogramowania. Korzysta z takiego oprogramowania, jakiego potrzebuje. Nie interesuje go ani sprzęt, ani środowisko pracy. Ma jedynie zapewniony dostęp do konkretnych, funkcjonalnych narzędzi – niekoniecznie połączonych ze sobą jednolitym interfejsem. Programy działają na serwerze dostawcy. Klient nie jest zmuszony nabywać na nie licencji. Płaci jedynie za każdorazowe ich użycie, a dostęp do nich uzyskuje na żądanie.
Communications as a Service (z ang. „komunikacja jako usługa”) – usługodawca zapewnia platformę pod telekomunikacyjne środowisko pracy.
Integration Platform as a Service (z ang. „platforma integracyjna jako usługa”) – platforma zapewniająca integrację pomiędzy różnymi usługami w chmurze.
Korzyści dla firm [ edytuj | edytuj kod ]
Z badania przeprowadzonego w 2011 na zlecenie Komisji Europejskiej przez International Data Corporation (IDC) wśród firm, które korzystają z chmury obliczeniowej, wynika, że oszczędności z tym związane wyniosły średnio 10–20% kosztów IT. W przypadku 36% przebadanych przedsiębiorstw wykorzystanie chmury obliczeniowej wygenerowało oszczędności w wysokości 20% wydatków na IT lub wyższej[7].
W celu szybkiego wdrożenia modelu chmury obliczeniowej w Unii Europejskiej w 2012 Komisja Europejska zaproponowała m.in. przyjęcie nowych ram prawnych dla ochrony danych oraz opracowanie jednolitych standardów regulujących ich przetwarzanie, co ma zwiększyć bezpieczeństwo świadczenia tej usługi[8].
Kluczowe korzyści[9]:
Pełna skalowalność – korzystając z chmury, użytkownik może dobrać odpowiednią ilość zasobów, jakie są mu potrzebne do odpowiedniego funkcjonowania. Jest to szczególnie istotne dla firm, w których zużycie mocy obliczeniowej jest różne, w różnych okresach.
– korzystając z chmury, użytkownik może dobrać odpowiednią ilość zasobów, jakie są mu potrzebne do odpowiedniego funkcjonowania. Jest to szczególnie istotne dla firm, w których zużycie mocy obliczeniowej jest różne, w różnych okresach. Niższe koszty – dzięki rozwiązaniom chmurowym nie trzeba ponosić inwestycji na infrastrukturę serwerową, a także jej obsługę. Obowiązki, które wiążą się z jej utrzymaniem, przechodzą na dostawcę usługi chmurowej. Co więcej, w przypadku usług chmurowych płaci się jedynie za zasoby, które są wykorzystane.
– dzięki rozwiązaniom chmurowym nie trzeba ponosić inwestycji na infrastrukturę serwerową, a także jej obsługę. Obowiązki, które wiążą się z jej utrzymaniem, przechodzą na dostawcę usługi chmurowej. Co więcej, w przypadku usług chmurowych płaci się jedynie za zasoby, które są wykorzystane. Pełny dostęp do danych – serwery ulokowane w chmurze obliczeniowej pozwalają na dostęp do danych z wielu urządzeń, w tym urządzeń mobilnych.
– serwery ulokowane w chmurze obliczeniowej pozwalają na dostęp do danych z wielu urządzeń, w tym urządzeń mobilnych. Bezpieczeństwo danych – chmura obliczeniowa cechuje się wysokim poziomem zabezpieczeń. Dane w niej zawarte są szyfrowane i udostępniane jedynie powołanym do tego osobom. Backup zabezpiecza przed nieplanowanym bądź przypadkowym usunięciem i utratą danych. Dodatkowo w przypadku kradzieży komputera istnieje możliwość zdalnego wyczyszczenia urządzenia.
Zobacz też [ edytuj | edytuj kod ]
Przetwarzanie danych informatycznych w chmurach obliczeniowych. Wybrane aspekty prawnokarne i procesowe
Wprowadzenie

Pojęcia takie jak: „chmura obliczeniowa” (ang. cloud computing), „wirtualna maszyna” (ang. virtual machine) oraz „dysk wirtualny” (ang. virtual disk) stosowane są do określenia zdalnego przetwarzania danych opartego na udostępnianiu użytkownikowi przez usługodawcę (zewnętrznego lub wewnętrznego) różnego rodzaju usług i zasobów technologii informacyjnych (np. środowiska uruchomieniowego programów, zasobów pamięci masowej itp.). W przypadku tych nowych metod przetwarzania danych prawie wszystkie zadania obliczeniowe, w tym instalacja, konfigurowanie i administrowanie usługami, odbywają się niezależnie od lokalizacji poszczególnych elementów fizycznych sprzętu komputerowego.
Wzrostowi zainteresowania powyższymi usługami towarzyszy pojawienie się wielu nowych problemów prawnych, które przekładają się m.in. na praktykę i zasady działania organów ścigania i karania. W ramach wykonywania różnego rodzaju czynności operacyjno-rozpoznawczych, dochodzeniowo-śledczych czy analityczno-informacyjnych pojawia się bowiem w szczególności konieczność uwzględnienia, że dane informatyczne, w tym m.in. elektroniczne zapisy wiadomości przekazywanych poprzez chmurę obliczeniową, mogą być zapisywane na kilkunastu współdzielonych urządzeniach, w swoistej „chmurze serwerów” zlokalizowanych w różnych państwach.
Takie uniezależnienie systemów teleinformatycznych od funkcjonowania klasycznego środowiska pracy opartego na pojedynczej stacji roboczej i jednym systemie operacyjnym nasuwa przede wszystkim pytanie o zasadność reinterpretacji tradycyjnego rozumienia miejsca popełnienia przestępstwa oraz zabezpieczenia mienia w celach dowodowych, które wiąże się z przeszukaniem, jak i zabezpieczeniem danych przechowywanych w pojedynczym systemie informatycznym lub na nośnikach zlokalizowanych w jednym państwie.
Niniejsze opracowanie zostało podzielone na trzy części, poświęcone odpowiednio aspektom technicznym, prawnokarnym i procesowym związanym z przetwarzaniem danych informatycznych w chmurze.
1. Aspekty techniczne funkcjonowania chmury obliczeniowej
Chmura obliczeniowa bazuje na wielu koncepcjach wykorzystywanych już od pewnego czasu w branży związanej z technologiami informacyjnymi (ang. information technology, dalej: IT), w tym w szczególności na architekturze zorientowanej na usługi informatyczne (ang. Service-Oriented Architecture
Główną funkcją chmury obliczeniowej jest dostarczanie na życzenie użytkownika różnego rodzaju usług. Do tych najpopularniejszych należą:
a) chmura aplikacyjna (ang. cloud applications), gdzie znajdują się usługi związane z dostarczaniem i dystrybucją oprogramowania,
b) chmura ze „środowiskiem oprogramowania” (ang. Cloud Software Environment, która też jest określana jako PaaS – Platform as a Service), a więc usługi polegające na udostępnianiu przez dostawcę wirtualnego środowiska (platformy) pracy,
c) chmura z infrastrukturą do oprogramowania (ang. Cloud Software Infrastructure) obejmująca:
infrastrukturę informatyczną, czyli sprzęt, serwery i komponenty sieci odpowiedzialne za uruchamianie istniejących aplikacji i systemów operacyjnych (ang. IaaS – Infrastructure as a Service
usługi związane z przechowywaniem i gromadzeniem danych oraz udostępnianie ich na żądanie użytkownika (ang. DaaS – Data as a Service);
usługi związane z zapewnieniem optymalizacji pracy programów poprzez kontrolę ich środowiska działania i procesu translacji kodu (ang. CaaS – Communications as a Service
Użytkownik może w łatwy sposób zmieniać zakres usług, np. zwiększyć pojemność przestrzeni dyskowej służącej do przechowywania danych czy zmieniać liczbę wykorzystywanych rdzeni CPU i publicznych numerów IP.
Dostęp do usług świadczonych w chmurze obliczeniowej uzyskuje się poprzez komputer bądź specjalne urządzenie (terminal komputerowy) wraz z odpowiednim oprogramowaniem typu klient, które umożliwia obsługę aplikacji stworzonej w architekturze klient–serwer. Wymagania dla urządzeń klienckich są zazwyczaj niewielkie, nawet zaś w przypadku konieczności modyfikacji czy rozbudowy ze względu na wyższe wymogi funkcjonalne aplikacji po stronie klienta nie pojawia się konieczność modyfikacji jego infrastruktury IT. Podstawowe komponenty wymagane do przetwarzania danych, takie jak procesor, twardy dysk czy oprogramowanie, są bowiem udostępniane przez . Szczególną cechą wskazanych usług jest zatem tzw. wirtualizacja, a więc oddzielenie warstwy logicznej od warstwy fizycznej systemu informatycznego, dzięki połączeniu wirtualnych maszyn w jeden fizyczny serwer oraz uniezależnieniu funkcjonowania systemu IT użytkownika od funkcjonowania klasycznego środowiska pracy, opartego zazwyczaj na pojedynczej stacji roboczej i jednym systemie .
Kolejną cechą charakteryzującą przetwarzanie w chmurze obliczeniowej jest to, że dane informatyczne (np. pliki zawierające dokumenty tekstowe, programy komputerowe, sterowniki itp.) w czasie przesyłu do użytkownika mogą być w międzyczasie zapisywane (także tymczasowo) w kilku miejscach, tzn. na serwerach, które mogą być zlokalizowane w różnych . Taka dekoncentracja (rozproszenie) zasobów informatycznych dokonywana jest głównie ze względów funkcjonalnych i jest związana z charakterystyką techniczną chmury obliczeniowej, która bazuje na wyszukiwaniu optymalnego miejsca zapisu. Miejscem stałego zapisu danych nie zawsze będzie przy tym komputer, z którego korzysta użytkownik, ponieważ dzięki chmurze może on uzyskać dostęp do danych, które są gromadzone w zupełnie innym miejscu.
W powyższym układzie użytkownik nie tylko nie jest właścicielem sprzętu, ale zazwyczaj nawet nie zna jego lokalizacji, co więcej, nie musi on także ani znać procesów związanych z przetwarzaniem danych, ani wiedzieć, który sprzęt komputerowy w danym momencie faktycznie go obsługuje, pomimo że takie informacje mogą mieć istotne znaczenie dla mających zastosowanie ram prawnych. Zupełnie inaczej funkcjonowanie chmury obliczeniowej muszą oceniać organy ścigania, ponieważ ustawodawca w wyraźny sposób odróżnia zasady uzyskiwania danych informatycznych przechowywanych lokalnie od tych dostępnych zdalnie. Z powodu konieczności określenia lokalnego miejsca zapisu danych utrudnione jest m.in. określenie właściwości miejscowej sądu czy też kompetencji poszczególnych organów ścigania.
2. Aspekty prawnokarne
Ze względu na to, że dla chmur obliczeniowych charakterystyczne jest przede wszystkim przesyłanie danych pomiędzy systemem komputerowym użytkownika a infrastrukturą informatyczną dostawcy chmury, ataki skierowane są przede wszystkim na poufność przetwarzanych informacji, prawo do dysponowania nią z wyłączeniem innych osób, a także na bezpieczeństwo jej przekazywania. Przechwytywane przez sprawcę dane informatyczne obejmują jednak nie tylko treść komunikacji, ale również dane o charakterze technicznym, w tym takie jak: schematy blokowe, architektury, hierarchie programu i interfejsy, biblioteki, katalogi, topologie, taksonomie, wewnętrzne kontrole, metadane Kwalifikacja prawna takiego czynu sprawcy może jednak budzić wątpliwości, ponieważ przepis art. 267 § 1 k. stawia dwa warunki konieczne do dokonania przestępstwa: naruszenie lub ominięcie zabezpieczeń chroniących informacje oraz „uzyskanie dostępu do informacji”.
Analizując powyższe zagadnienie, należy zauważyć, że po pierwsze, konieczne jest wyraźne rozróżnienie pomiędzy informacją oraz danymi . Nie wszystkie dane zawierają informację skierowaną do użytkownika np. w postaci elementów komunikacji, angażując jego zdolności percepcyjne. Dane informatyczne stanowią bowiem zarówno element komunikacji, jak i przetwarzania, interpretacji w programie komputerowym lub jego części, mogą zarówno być przeznaczone do wykonania odpowiedniej funkcji, np. wyświetlenia informacji na ekranie komputera użytkownika, jak również stanowić część procesu lub/i operacji wykonanych przez program komputerowy, komputer, system komputerowy lub sieć. Po drugie, na gruncie polskiego ustawodawstwa brak jest definicji danych informatycznych, która obejmowałaby również program komputerowy. Powoduje to wątpliwość, czy pojęcie to obejmuje te elementy programu komputerowego, które nie mają charakteru danych informatycznych. Jak bowiem zauważa się w literaturze przedmiotu, programy komputerowe zawierają nie tylko elektroniczne zapisy informacji bezpośrednio skierowane do użytkownika, ale mogą także przybrać formę czytelną wyłącznie dla systemu komputerowego (są przetwarzane przez procesor). Do danych komputerowych nie będzie można przykładowo zakwalifikować takich elementów programu komputerowego, jak: algorytm, struktura programu, interfejsy (łącza), protokoły komunikacyjne, metody obróbki danych komputerowych Po trzecie, ustawodawca dodatkowo ogranicza ochronę jedynie do tych danych informatycznych będących elektronicznym zapisem informacji, które są elektroniczne, magnetyczne, informatyczne lub też inaczej, szczególnie zabezpieczone (np. zaszyfrowane).
W kontekście powyższych uwag należy stwierdzić, że ochrona przed przechwytywaniem i zapisywaniem danych informatycznych przyjęta na gruncie polskiego ustawodawstwa jest obecnie fragmentaryczna. Wątpliwe jest przede wszystkim, czy dyspozycją tego przepisu objęte będzie przechwycenie danych na temat samego faktu komunikacji pomiędzy poszczególnymi osobami, przebiegu i charakteru procesu transmisji (np. danych co do faktu wysłania e-maila, daty, czasu trwania połączenia telefonicznego itp.). W tym zakresie przepis ten nie jest także zgodny z art. 6 (niezgodne z prawem przechwytywanie) dyrektywy Parlamentu Europejskiego i Rady 2013/40/UE z dnia 12 sierpnia 2013 r. dotyczącej ataków na systemy informatyczne i zastępującej decyzję ramową Rady 2005/222/WSiSW (Dz.U. UE L z dnia 14 sierpnia 2013 r.), który nakazuje penalizację przechwytywania środkami technicznymi niepublicznych przekazów danych komputerowych, a nie informacji, i to jeszcze szczególnie zabezpieczonej.
Atak hackera przeciwko chmurze obliczeniowej może skutkować także nielegalną ingerencją w prawidłowe funkcjonowanie systemu teleinformatycznego, jak i w dostępność określonych informacji. W przypadku zniszczenia, uszkodzenia, zmiany lub utrudnienia zapoznania się z informacją zastosowanie może znaleźć art. 268 k.k. (utrudnianie dostępu i niszczenie informacji), w przypadku zaś utrudniania dostępu do danych informatycznych lub zakłócania pracy systemu komputerowego, np. poprzez przejęcie nad nim kontroli – art. 268a k.k. (ingerencja w dane i system) lub art. 269a k.k. (zakłócanie pracy systemu komputerowego lub sieci teleinformatycznej). Również te przepisy obarczone są pewnymi mankamentami utrudniającymi ich zastosowanie w przypadku ataku na chmurę obliczeniową.
Przestępstwo stypizowane w art. 268 k.k. może być zrealizowane w kilku odmianach, które polegają na zniszczeniu (tj. całkowitym unicestwieniu), uszkodzeniu („zepsuciu”), usunięciu lub zmianie zapisu istotnej informacji, przy czym chodzi tu o ingerencję dotyczącą wszelkich urządzeń lub przedmiotów zawierających zapis . Spektrum możliwych odmian czynności wykonawczej jest niezwykle szerokie i może obejmować np. zachowania polegające na wprowadzeniu szczególnych utrudnień dostępu do informacji przechowywanych na wirtualnym dysku poprzez szczególne obciążenie systemu komputerowego będące efektem jego zawirusowania lub też „wprowadzenia” do systemów trojana lub innych programów typu malware. Jednakże – jak słusznie zauważa się w literaturze przedmiotu – integralność zapisu informacji chroniona jest tylko wówczas, gdy następstwem nieuprawnionej ingerencji jest udaremnienie lub znaczne utrudnienie dysponentowi informacji lub innej osobie uprawnionej zapoznania się z informacją. Tym samym nie każde „zawirusowanie” systemu operacyjnego, jego rekonfiguracja, instalacja „tylnych drzwi” lub też wprowadzenie do systemu komputerowego „konia trojańskiego” narusza dyspozycję art. 268 § 2 k.k. lub § 3 tego przepisu, nawet gdy powoduje znaczną szkodę . Podobnie w przypadku modyfikacji programu komputerowego odpowiedzialnego za właściwe funkcjonowanie wirtualnej maszyny czy też innych funkcji związanych z przetwarzaniem danych w chmurze sprawcy będzie można postawić zarzut na podstawie art. 268 § 2 lub 3 k.k. jedynie wówczas, kiedy wpłynie to również na zakłócanie lub uniemożliwianie automatycznego przetwarzania, gromadzenia lub przekazywania danych informatycznych.
Podobnie zastosowanie art. 268a k.k., w przypadku ataków skierowanych na chmurę obliczeniową, może powodować pewne utrudnienia, ponieważ o popełnieniu tego przestępstwa decyduje „istotne zakłócanie” lub „uniemożliwianie” automatycznego przetwarzania, gromadzenia lub przekazywania danych informatycznych, nie zaś sama nieupoważniona interakcja z jakimkolwiek urządzeniem służącym do przechowywania, przekazywania lub gromadzenia danych lub programów komputerowych. Również w przypadku tego przepisu jego mankamentem jest brak definicji ustawowej pojęcia „dane informatyczne”, która np. na wzór definicji zawartej w art. 1b Konwencji Rady Europy o cyberprzestępczości (ETS/STE No. 185) w sposób wyraźny wolą ustawodawcy nadałaby temu pojęciu szersze znaczenie, obejmujące również programy komputerowe.
Brak definicji ustawowej pojęcia „dane informatyczne”, czy też brak wyraźnego uznania za dobro chronione przez art. 269a k.k. również procesu przetwarzania i gromadzenia programów komputerowych, powoduje sytuację, w której chronione będą tylko niektóre zakłócenia pracy systemów komputerowych chmury obliczeniowej. Nie każdy przecież sabotaż komputerowy wiąże się z niszczeniem, uszkodzeniem, usunięciem czy zmianą danych . Na przykład wirusy określane jako bakterie lub też króliki (ang. backtery, rabbits) to programy, które w zasadzie nie niszczą plików ani nie modyfikują danych tekstowych. Ich jedynym celem jest samo kopiowanie z wykorzystaniem mocy obliczeniowej procesora, prowadzące do jego przeciążenia.
Kolejny problem, który ujawnia się w kontekście chmury obliczeniowej, jest związany z właściwym określeniem miejsca popełnienia czynu zabronionego, które z punktu widzenia prawa karnego międzynarodowego ma istotne znaczenie zarówno ze względów materialnoprawnych, jak też . Pozwala to bowiem z jednej strony udzielić odpowiedzi na pytanie, czy znajdzie zastosowanie polska ustawa karna, czy też obca, z drugiej zaś strony ustalić właściwość miejscową sądu uprawnionego do rozpoznania sprawy, zapobiegając ewentualnym sporom kompetencyjnym organów procesowych.
Polskie prawo karne w odniesieniu do miejsca popełnienia przestępstwa przyjmuje tak zwaną teorię wszędobylstwa (wielomiejscowości), według której przestępstwo może być popełnione w różnych miejscach. Miejsce popełnienia przestępstwa określone jest w art. 6 § 2 k.k., według którego przestępstwo uważa się za popełnione w miejscu:
gdzie sprawca działał lub zaniechał działania, do którego był obowiązany; gdzie skutek przestępny nastąpił; gdzie według zamiaru sprawcy skutek miał nastąpić.
Przyjęcie zasady „wielomiejscowości” rozszerza znacznie polską jurysdykcję na podstawie zasady terytorialności. W myśl tej zasady wystarczy, by jeden z elementów przestępstwa dotknął terytorium danego państwa, aby mogło ono uznać, że cały czyn podlega jego jurysdykcji.
Wskazane powyżej przestępstwa komputerowe nie powinny budzić większych wątpliwości przy określeniu miejsca działania sprawcy. W szczególności polska ustawa będzie znajdowała zastosowanie w sytuacji, w której sprawca, działając z terytorium Polski, będzie manipulował systemem komputerowym znajdującym się w innym państwie czy też system ten atakował.
Dużo większe wątpliwości może powodować określenie miejsca skutku, jak również zamierzonego skutku. W przypadku ataków skierowanych na chmurę obliczeniową powstaje w szczególności pytanie, czy należy brać pod uwagę wszystkie miejsca, w których wystąpiły jakiekolwiek negatywne następstwa przestępstwa, oraz wszystkie miejsca rezultatów poszczególnych etapów działania sprawcy. Pojedyncze działanie sprawcy może bowiem wywołać skutek na terytorium kilku państw, w których znajduje się np.:
a) system informatyczny służący podniesieniu efektywności (przyśpieszeniu) poprzez czasowe i pośrednie zapisywanie informacji pochodzących z innych serwerów;
b) serwer, za pomocą którego sprawca przesyła dane (tzw. uploading) w celu ich zapisu na wirtualnym dysku;
c) serwer hostujący, na którym dochodzi do trwałego zapisu danych;
d) system informatyczny, za pomocą którego dochodzi do wykorzystania danych informatycznych (np. miejsce odbioru treści, pobrania plików itp.).
Na tym tle pojawia się przede wszystkim wątpliwość, czy zbyt szeroka interpretacja miejsca skutku nie narusza zasady nullum crimen, nulla poena sine lege, która na gruncie polskiego ustawodawstwa znajduje swe zakotwiczenie bezpośrednio w art. 42 pkt 1 Konstytucji RP oraz w art. 1 § 1 k.k. Z punktu widzenia wymogu przewidywalności czynu zabronionego dla zastosowania polskiej ustawy karnej konieczne jest istnienie normy prawnokarnej, która musi w rzeczywistości obowiązywać w miejscu popełnienia przestępstwa, a więc konstytuować odpowiedzialność od strony materialnej i procesowej. W rezultacie konflikty przy określeniu terytorialnego obowiązywania norm prawnokarnych przy przestępstwach o charakterze pozaterytorialnym wymagają zarówno uwzględnienia panującego porządku prawnego w miejscu popełnienia przestępstwa, jak i istnienia realnego związku z państwem stwierdzającym własną jurysdykcję, realizując w ten sposób treść moralną wyrażającą się w założeniu, by sprawca przestępstwa odpowiadał za nie tam, gdzie je w rzeczywistości .
Powyższe uwagi skłaniają do wniosku, że o właściwości polskiej ustawy nie powinno decydować jedynie to, że w danym państwie znajdują się takie części infrastruktury technologicznej chmury obliczeniowej, które są odpowiedzialne jedynie za transmisję (przesyłanie) danych pomiędzy poszczególnymi serwerami, czy też odpowiedzialne jedynie za incydentalny zapis tych danych na nośniku komputerowym. Należy bardziej zwrócić uwagę, gdzie w rzeczywistości doszło do nastąpienia skutku, np. do zniszczenia lub zniekształcenia zapisu istotnej informacji (całości lub części) lub uszkodzenia systemu komputerowego lub programu umożliwiającego zapoznanie się z informacją (art. 268 k.k.). Wszystko to powoduje konieczność każdorazowej oceny, jakie narzędzia i środki techniczne odpowiedzialne za wykonywanie określonych zadań związanych z przetwarzaniem danych informatycznych oraz w jakim zakresie stały się przedmiotem ataku hackera. Warto przy tym zauważyć, że w wielu przypadkach, w czasie śledztwa i dochodzenia, określenie właściwości miejscowej wymagać będzie współpracy z dostawcą usługi, bez którego określenie miejsca ataku, jak również miejsca fizycznego zapisu danych nie będzie możliwe.
3. Aspekty procesowe
Regulacje dotyczące pozyskiwania dowodów elektronicznych znajdują się przede wszystkim w art. 218a, art. 236a i art. 241 k.p Jest oczywiste, że danych informatycznych nie należy traktować jako rzeczy w rozumieniu karnoprocesowym, ponieważ stanowią one odrębną kategorię niematerialnych źródeł . Przepisy rozdziału 25 („Zatrzymanie rzeczy. Przeszukanie”), zgodnie z art. 236a k.p.k., znajdują do nich jednak odpowiednie zastosowanie.
W przypadku pozyskiwania danych przetwarzanych w chmurze zastosowanie znajdzie, po pierwsze, art. 217 k.p.k. w zw. z art. 236a, który dopuszcza żądanie wydania danych przechowywanych na urządzeniu, w systemie lub na nośniku od dysponenta lub użytkownika tegoż urządzenia, nośnika lub systemu. Po drugie, możliwe będzie także przeszukanie urządzenia lub systemu informatycznego w celu znalezienia danych mogących stanowić dowód w sprawie (art. 236a w zw. z art. 219 k.p.k.). Jak słusznie zauważa się w literaturze przedmiotu, nie chodzi tu o przeszukanie w znaczeniu tradycyjnym, ale o penetrację (przy użyciu odpowiedniego oprogramowania) zawartych w urządzeniu lub systemie danych w celu znalezienia i zabezpieczenia ich dla . Po trzecie, możliwe jest także żądanie wydania korespondencji elektronicznej, w tym załączonych do niej plików, przesłanej w systemie elektronicznym, oraz wykazów połączeń teleinformatycznych (art. 236a w zw. z art. 218 k.p.k . Odpowiednie stosowanie regulacji z art. 217–219 k.p.k. oznacza, że dane informatyczne, które będą pozyskiwane, muszą być w pierwszej kolejności zgromadzone, tzn. zapisane na odpowiednim nośniku lub też na urządzeniu, w systemie komputerowym, czy też na serwerze, nawet wówczas, gdy zapis taki miał charakter przejściowy, incydentalny.
Jedną z technik pozwalających analizować pakiety przesyłane przez sieć komputerową pod względem treści jest tzw. głęboka inspekcja pakietów (ang. Deep Packet Inspection). Umożliwia ona m.in. podsłuchiwanie treści wiadomości przesyłanych przez . Na tym tle pojawia się pytanie, czy na gruncie polskiego ustawodawstwa możliwe będzie wykorzystanie tej techniki podsłuchu. W myśl art. 241 k.p.k. przepisy rozdziału 26 („Kontrola i utrwalanie rozmów”) stosuje się odpowiednio do kontroli oraz do utrwalania przy użyciu środków technicznych treści innych rozmów lub przekazów informacji, w tym korespondencji przesyłanej pocztą . Tym samym zastosowanie tego rodzaju podsłuchu wydaje się dopuszczalne. Warto jednak zauważyć, że ustawa ogranicza pod względem przedmiotowym stosowanie podsłuchu do enumeratywnie wyliczonych w § 3 art. 237 k.p.k. najcięższych przestępstw. Takie przedmiotowe ograniczenie podsłuchu komputerowego powoduje sytuację, w której jego zastosowanie będzie wyłączone w stosunku do najczęstszych . Obecnie zakresem zastosowania kontroli i utrwalania treści rozmów objęte będą mogły być jedynie sprawy o szpiegostwo lub ujawnienie informacji niejawnych o klauzuli tajności „tajne” lub „ściśle tajne”, przechowywanych w chmurze obliczeniowej.
Wskazane powyżej przepisy dają możliwość przechwytywania danych informatycznych w chmurze obliczeniowej niezależnie od tego, czy znajdują się one w jednym, czy też kilku miejscach, o ile dane są zapisywane lub przesyłane na terytorium . Pomimo że wskazane ograniczenie terytorialne możliwości pozyskiwania danych informatycznych nie wynika wprost z odpowiednich regulacji normatywnych, ograniczenie takie wyprowadzić jednak należy z zasady poszanowania suwerenności, nienaruszalności granic i integralności terytorialnej państw.
Wszystko to powoduje, że nie tylko lokalizacja oraz ujęcie przestępcy, ale przede wszystkim zgromadzenie dowodów umożliwiających pociągnięcie go do odpowiedzialności oraz stwierdzenie, czy będzie on podlegał pod ustawę karną danego państwa, to realne problemy, z jakimi konfrontowane będą coraz częściej organy ścigania i karania. Wskazane trudności pogarsza dodatkowo niejednolity reżim ochrony prawnej przyznawany poszczególnym dobrom prawnym w poszczególnych państwach, w których zlokalizowana może być infrastruktura techniczna . Może to bowiem przyczyniać się do powstania wielu praktycznych problemów związanych z możliwością pociągnięcia do odpowiedzialności karnej osób uważanych za przestępców w części państw o bardziej restrykcyjnych regulacjach normatywnych, z drugiej zaś strony chronionych przez inne państwa, z racji przyznania im w tych państwach większej ochrony. Warto przy tym zauważyć, że dostęp do danych informatycznych jest także często znacznie utrudniony ze względu na stosowanie różnego rodzaju technik zabezpieczenia informacji przed nieuprawnionym dostępem do .
Naturalną odpowiedzią na prezentowane zjawisko powinno być zatem zarówno umiędzynarodowienie jego , jak i podjęcie współpracy z organami ścigania z innych . Prowadzenie czynności śledczych na terytorium innego państwa może odbywać się w drodze pomocy prawnej w trybie określonym w rozdziale 62 k.p.k. („Pomoc prawna i doręczenia w sprawach karnych”). Postępowanie w takim trybie wymaga jednak spełnienia wielu formalności i postępowania zgodnie z określonymi procedurami.
Próbę rozwiązania problemów ujawniających się na tym obszarze podjęto m.in. w podpisanej w dniu 23 listopada 2001 r. w Bukareszcie pod auspicjami Rady Europy Konwencji o cyberprzestępczości, która jest obecnie uznawana na szczeblu międzynarodowym za najbardziej kompletny zbiór norm międzynarodowych w zakresie ścigania cyberprzestępstw. W tym dokumencie, w rozdziale III Konwencji („Współpraca międzynarodowa”), wskazano liczne instrumenty międzynarodowe, które powinny znaleźć zastosowanie w ramach współpracy w sprawach karnych. Zwrócono także uwagę na potrzebę wyznaczenia punktów kontaktowych dostępnych 24 godziny na dobę przez 7 dni w tygodniu w celu zapewnienia natychmiastowej pomocy w prowadzeniu czynności śledczych lub postępowań odnoszących się do przestępstw związanych z systemami i danymi informatycznymi lub dla zbierania dowodów w postaci elektronicznej dotyczących przestępstw (art. 35). Należy przy tym zauważyć, że zastosowanie w praktyce wskazanych instrumentów prawnych jest znacznie ograniczone ze względu na zauważalny powolny proces ratyfikacji Konwencji .
W Unii Europejskiej, będącej „przestrzenią wolności, bezpieczeństwa i sprawiedliwości bez granic wewnętrznych” [art. 3 ust. 2 Traktatu o Unii Europejskiej (TUE), art. 67 Traktatu o funkcjonowaniu Unii ], istnieje wiele instrumentów prawnych ułatwiających współpracę z organami ścigania z innych państw. Do tych najważniejszych na analizowanym obszarze zaliczyć należy ułatwienia w zakresie pomocy prawnej (art. 10 Konwencji ustanowionej przez Radę zgodnie z art. 34 Traktatu o Unii Europejskiej o pomocy prawnej w sprawach karnych pomiędzy państwami członkowskimi Unii ), wzajemne dopuszczanie dowodów, przesłuchanie świadków oraz biegłych w formie konferencji telefonicznej (art. 11 Konwencji), ułatwienia w pozyskiwaniu, zamrażaniu i przekazywaniu dowodów (np. art. 18 i n. Konwencji dotyczące przechwytywania przekazów telekomunikacyjnych) oraz możliwość prowadzenia eksterytorialnych śledztw [np. możliwość powołania wspólnych zespołów śledczych (art. 13 Konwencji) oraz prowadzenia operacji pod przykryciem (art. 14 Konwencji)]. System ten dysponuje przy tym wieloma strukturami czynnie zwalczającymi tego rodzaju przestępczość, opartymi głównie na sprawnie funkcjonującej współpracy pomiędzy adekwatnymi strukturami międzynarodowymi i poszczególnymi . Z tego też względu – jak zauważa M. Grecke – współpraca w zakresie pomocy prawnej wśród państw członkowskich UE w ostatnich latach uległa znaczącej poprawie i umożliwia aktywne przeciwdziałanie atakom hackerów. Znacznie gorzej wygląda jednak pomiędzy państwami spoza tego regionu, gdzie taka współpraca należy do .
Podsumowanie
Ze względu na to, że w przypadku chmur obliczeniowych, wirtualnych maszyn i dysków kwestia przesyłu i miejsca zapisu danych stanowi jedynie zagadnienie o charakterze technologicznym, zasadne wydaje się stwierdzenie, że określenie właściwości miejscowej w sprawach karnych nie powinno opierać się jedynie na bezwzględnym dążeniu do realizacji funkcji represyjno-prewencyjnej poprzez wykraczanie poza granice państwowe w sytuacji wystąpienia choćby najmniejszej części elementów stanu faktycznego przestępstwa na terytorium państwa, ale powinno przede wszystkim uwzględniać szczególny związek między zachowaniem sprawcy a terytorium danego państwa. Wskazanie takiego powiązania pomiędzy czynem sprawcy a terytorium, na którym działał lub zaniechał działania albo gdzie skutek stanowiący znamię czynu zabronionego nastąpił lub według zamiaru sprawcy miał nastąpić, może okazać się jednak dalece problematyczne, głównie ze względu na konieczność zwrócenia uwagi na mechanizm działania systemów informatycznych, w sposób uwzględniający nie tylko przyjęty w tych wypadkach modus operandi sprawców, ale także specyfikę poszczególnych rodzajów usług świadczonych w chmurze.
Wzrost zainteresowania chmurami obliczeniowymi postawił przed organami ścigania i karania wiele nowych problemów prawnych. Obecnie najpoważniejszym z nich wydaje się międzynarodowy charakter chmury obliczeniowej, który utrudnia w znaczący sposób prowadzenie śledztwa i pozyskiwanie dowodów elektronicznych. Należy przeto wyrazić nadzieję, że wzrost zainteresowania tym modelem przetwarzania danych zapoczątkuje dyskusję na temat potrzeby podjęcia międzynarodowej współpracy, wykraczającej także poza państwa UE.