Eksploracja Danych w Marketingu Spersonalizowanym – Big Data, Data Mining, skalowanie systemów IT
(PDF) Algorytmy eksploracji danych z baz danych
April 1988
(2) additional documentation describing lower-level modules used to implement a major tool of the Ada/SQL system. Section 1 contains introductory and background material. Section 2 is a description of the application scanner system dependencies, with discussions of the standards directory and files, file extensions, naming conventions of files, tables, and columns and the debug options. Section 3 contains the two types of documentation for the application scanner, with an overview of each file and then the actual file documentation.
The purpose of this IDA Memorandum Report is to describe additional documentation for the application scanner tool described in IDA Memorandum Report M-460, an Ada/SQL Application Scanner. In M-461, two types of information are presented: (1) the identification and description of the particular software of the application scanner which may be modified if rehosted to a different environment and ... [Show full abstract]
Analiza efektywności algorytmów eksploracji danych dla Microsoft SQL Server
Streszczenie:
Celem pracy była analiza dostępnych algorytmów MS SQL Server od wersji 2000 do 2017. Badanie dotyczyło tego, jak poszczególne wersje się zmieniały i jakie były różnice w działaniu algorytmów do eksploracji danych. Opisane zostały kroki procesu oraz metody eksplorowania danych. W rozdziale 3 jest krótki opis dostępnych algorytmów oraz wstęp do właściwej analizy. Rozdział 4 opisuje w teorii sposób implementacji i działania algorytmów. Rozdział piąty zawiera konkretna analizę algorytmów w MS SQL Server w wersjach 2005 do 2017. W podsumowaniu opisane zostały wnioski i ewentualne dalsze rozwinięcie analizy. The purpose of the work was the analysis of MS SQL Server from 2000 to 2017. The study concerned how it happens that the differences in the operation of algorithms for data mining change. The process steps and methods for data mining have been described. In Chapter 3 there is a short description of the available algorithms and an introduction to the proper analysis. Chapter 4 describes in theory the implementation and operation of algorithms. The fifth chapter contains a specific analysis of algorithms in MS SQL Server in versions 2005 to 2017. The conclusions summarize the conclusions and possible further development of the analysis.
Eksploracja Danych w Marketingu Spersonalizowanym – Big Data, Data Mining, skalowanie systemów IT
Share List
Marketing spersonalizowany (lub marketing jeden do jednego) polega na dostosowania oferty produktowej do preferencji konkretnych klientów. Mamy do czynienia z tym problemem, przykładowo, podczas przygotowywania „gazetek” produktowych przesyłanych do klientów drogą e-mailową (personalizacji ulotek drukowanych raczej nie stosuje się ze względu na wysokie koszty). Aby zminimalizować CPS (ang. Cost Per Sale – Koszt Transakcji / Sprzedaży) należałoby w każdej ofercie przedstawić takie produkty, dla których prawdopodobieństwo, że zostaną zakupione przez danego klienta jest największe. Innym przykładem tego zagadnienia jest prezentowanie komunikatów typu „Inni klienci zakupili również produkty X, Y i Z” na stronach sklepów internetowych. Rodzi to pytanie – jak określić, które produkty spośród całej oferty (często tysiące lub więcej pozycji asortymentowych) mają największą szansę powodzenia u danego klienta? W praktyce stosuje się głownie dwa podejścia w różnych wariantach i kombinacjach.
Doradcy, czyli K-Najbliższych Sąsiadów
Pierwszym sposobem jest zastosowanie dla każdego klienta, dla którego przygotowujemy ofertę algorytmu K-Najbliższych Sąsiadów lub tzw. doradców.
Można tutaj stosować różne warianty funkcji pomiaru odległości, lecz podstawowa zasada pozostaje niezmienna: klienci są tym bliżej siebie, im więcej identycznych produktów znajdujemy w ich historii zakupów. Wynika z tego, że zawodowi hydraulicy kupujący podobny asortyment (rury, pakuły, zawory itp.) będą leżeli stosunkowo blisko siebie, a w znacznej odległość od gospodyń domowych – kupujących produkty z zupełnie innych grup.
Należy tutaj również uwzględnić pewne zjawisko i je odpowiednio kompensować. Mogą bowiem znaleźć się w bazie produkty, które kupowane są przez wszystkie grupy konsumentów. Przy obliczaniu odległości pomiędzy konsumentami powinno uwzględniać się prawdopodobieństwo wystąpienia danego produktu w całej populacji klientów i wyróżniać go lub obarczać pewną karą. Przykładowo:
Klient A i klient B kupili kiedyś cukier. Prawdopodobieństwo, że klient kupił kiedykolwiek cukier wynosi, przykładowo, 50% – produkt ten nie jest więc charakterystyczny dla konkretnej grupy klientów; jest raczej przykładem produktu dość popularnego i powinien mieć mniejszy wpływ na odległość pomiędzy klientami;
Klient A i klient B kupili kiedyś wkrętarkę udarową. Prawdopodobieństwo zakupu tego produktu dla klienta wynosi 1,5% – produkt ten nie jest więc tak często kupowany jak cukier i powinien zostać wyróżniony – mieć większy wpływ na zmniejszenie odległości pomiędzy tymi klientami.
Kolejnym krokiem, po określeniu K najbliższych sąsiadów, jest odnalezienie takich produktów, które zostały jak najczęściej kupowane przez znalezionych doradców, a nie zostały jeszcze zakupione przez analizowanego klienta, do którego kierujemy korespondencję z ofertą.
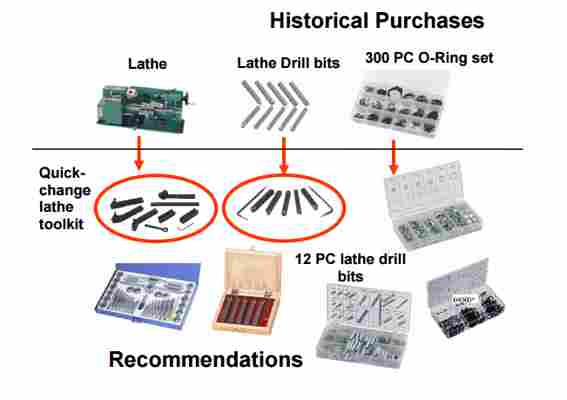
Efekty pracy tego algorytmu mogą być zaskakująco trafne. Poniższa ilustracja pochodzi z artykułu opisującego podejście firmy Central Purchasing, Inc. do stworzenia rozwiązania przygotowującego oferty dla klientów. Oryginalny dokument w j. angielskim można znaleźć tutaj.
We wspomnianym artykule przytoczono również zestawienie wyników pokazujących jak ogromny wzrost skuteczności zanotowano w porównaniu z marketingiem niespersonalizowanym – tak jeszcze popularnym wśród mniejszych firm.
Produkty Powiązane – Analiza Koszyka
Kolejnym podejściem do problemu jest tzw. Analiza Koszyka. Opiszę je tylko skrótowo, aby pokazać alternatywę do podejścia poprzedniego.
Analiza koszyka polega na ustaleniu które produkty są najczęściej kupowane w grupie, co może wynikać z ich powiązania. Przykładowo cukier i kawa, wiertarka oraz zestaw wierteł itp. Reguły tych powiązań pomiędzy produktami można zapisać następująco:
cukier kawa oraz wiertarka zestaw wierteł
Takie relacje mogą zachodzić zupełnie przypadkowo, stąd potrzeba pomiaru parametrów takich powiązań. Stosuje się tutaj dwa podstawowe parametry – wsparcie, które mówi o tym jak często te produkty występują razem w koszyku oraz ufność, które mówi o tym ilu klientów, którzy zakupili produkt pierwszy, zakupiło również produkt drugi.
Przykładowo:
cukier kawa [wsparcie = 5%, ufność = 74%]
oznacza, że 5% procent wszystkich zakupów w sklepie zawierało oba powyższe produkty, a w 74% przypadków zakupu cukru, zakupiono również kawę. Taki współczynnik ufności świadczy o występowaniu jakiegoś powiązania pomiędzy produktami, a wiedza o tym może być użyta przy projektowaniu kampanii reklamowych, rozmieszczeniu regałów sklepu oraz promocji.
Jednym z najbardziej popularnych algorytmów określania asocjacji między produktami jest tzw. algorytm „Apriori„.
Share List